正则表达式学习
正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子。
💎基本语法
基本匹配
基本匹配和一般搜索基本相同,区别大小写!!
元字符
| 元字符 | 描述 |
|---|---|
| . | 匹配任意单个字符除了换行符。 |
| [ ] | 字符种类。匹配方括号内的任意字符。 |
| [^ ] | 否定的字符种类。匹配除了方括号里的任意字符 |
| * | 匹配>=0个重复的在*号之前的字符。 |
| + | 匹配>=1个重复的+号前的字符。 |
| ? | 标记?之前的字符为可选. |
| {n,m} | 匹配num个大括号之前的字符或字符集 (n <= num <= m). |
| (xyz) | 字符集,匹配与 xyz 完全相等的字符串. |
| | | 或运算符,匹配符号前或后的字符. |
| \ | 转义字符,用于匹配一些保留的字符 [ ] ( ) { } . * + ? ^ $ \ | |
| ^ | 从开始行开始匹配. |
| $ | 从末端开始匹配. |
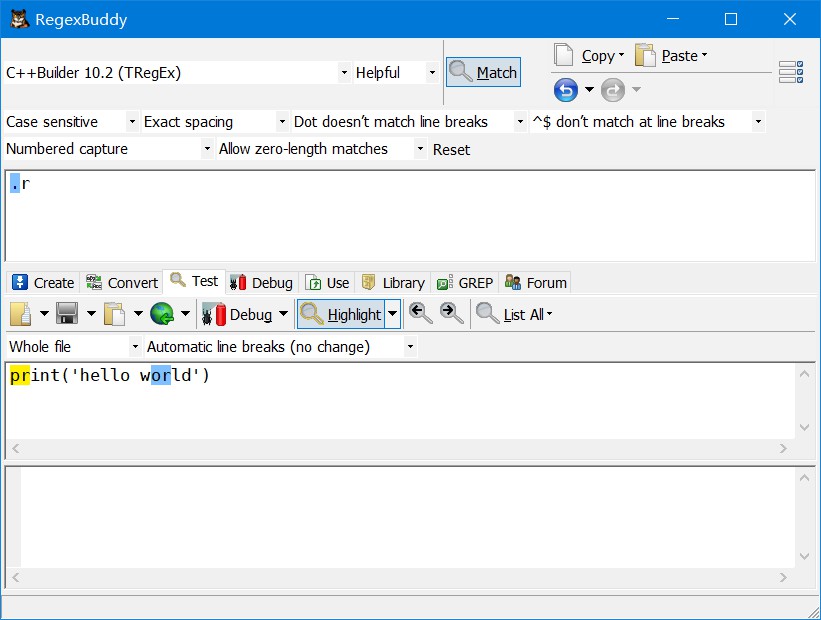
运算符 .
匹配任意单个字符除了换行符
.r匹配pr和or
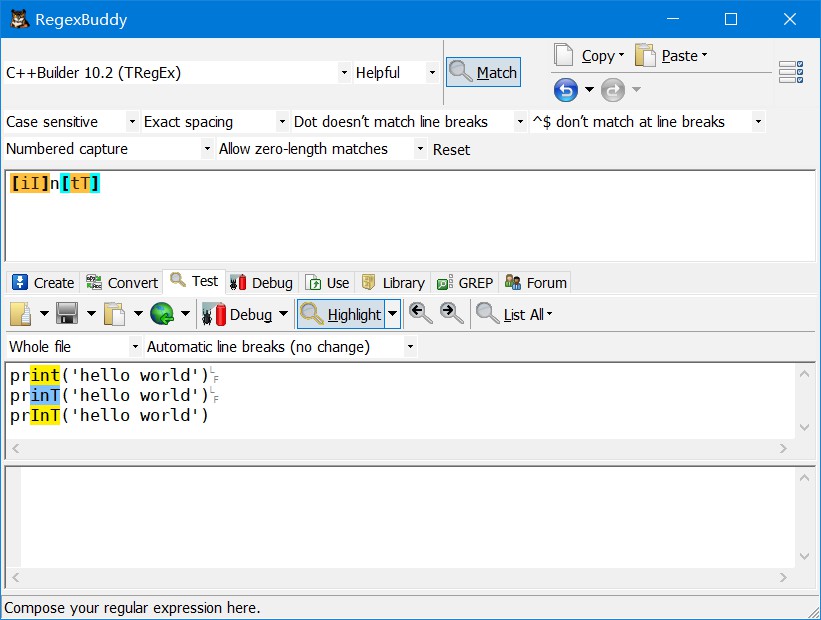
运算符 []
匹配方括号内的任一字符
[a-z]、[A-C]、[0-9]、[a-z0-9]等表达式可以用来指定字母或数字的范围,常用于匹配、区分大小写、区分字母与数字。
[iI]n[tT]匹配int、inT、InT
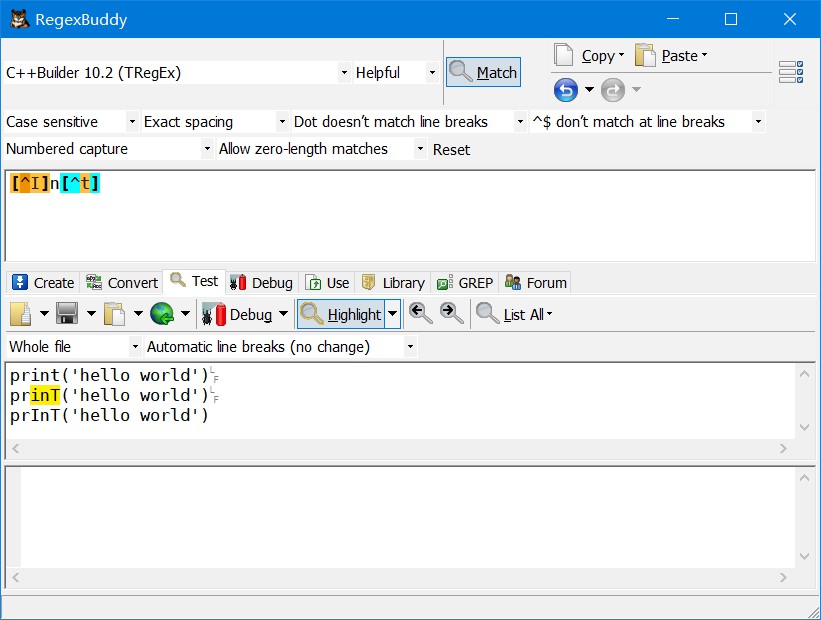
运算符 [^]
匹配非方括号内的任一字符
[^I]n[^t]排除int和InT
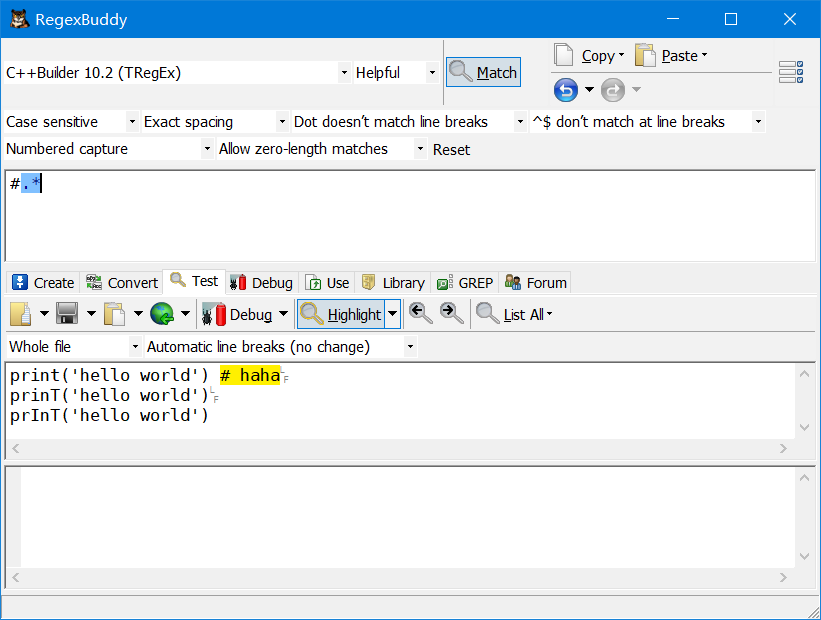
运算符 *
匹配>=0个重复的在*号之前的字符,常用
.*匹配一段字符
#.*匹配 python 代码注释
运算符 +
匹配>=1个重复的+号前的字符,常用.+匹配至少一个字符的字符串
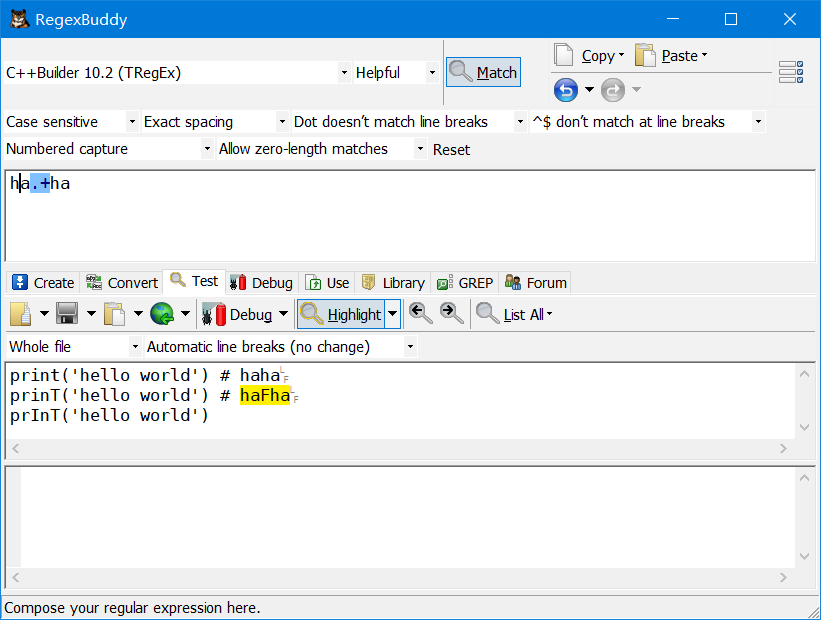
ha.+ha匹配ha和ha中间至少一个字符的字符串
运算符 ?
标记?之前的字符为可选(紧跟的字符)
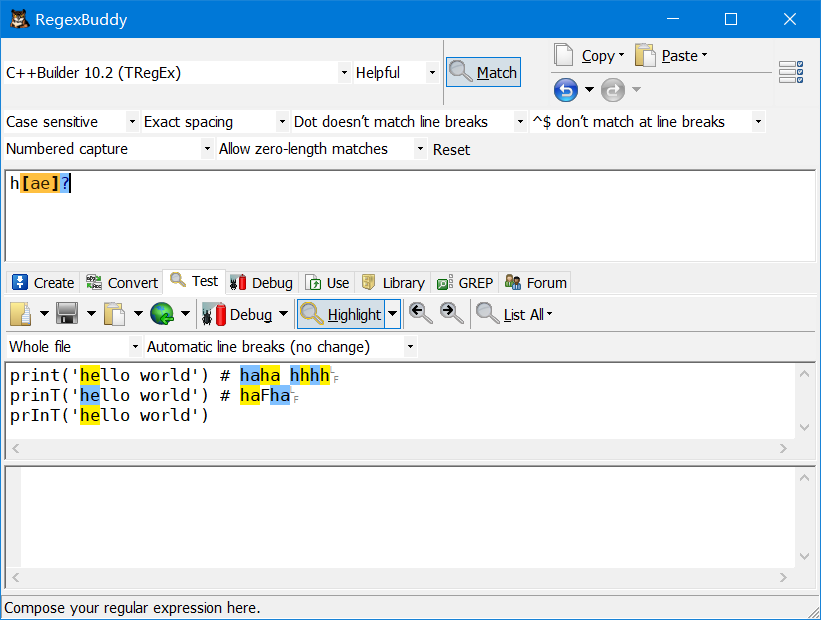
h[ae]?匹配时[ae]为可选,即匹配h和h[ae]
运算符 {n,m}
匹配num个大括号之前的字符或字符集 (n <= num <= m),单参数{num}时相当于{num,num},{num,}时相当于至少num个
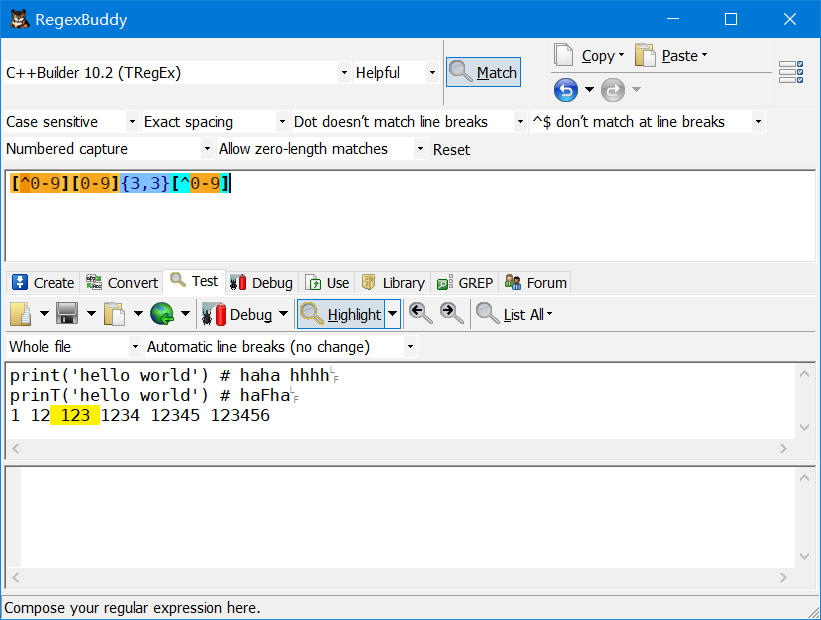
匹配三位数且两边不是数字
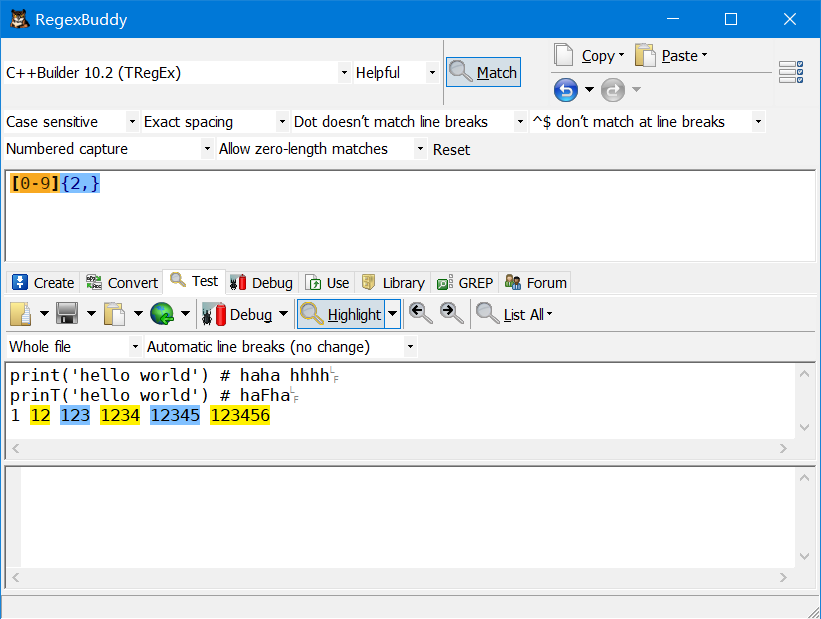
匹配多于两位数的数字
运算符 (xyz)
特征标群,(xyz)中的字符集划定为一个整体
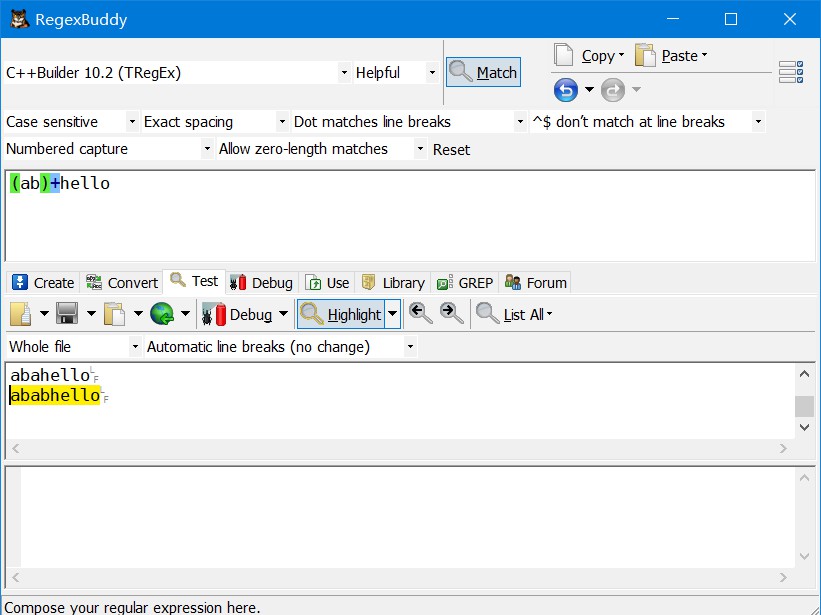
(ab)+hello匹配hello结尾前面紧接着ab的字符串
运算符 |
或运算符,匹配符号前或后的字符
print|hello匹配print或hello
运算符 \
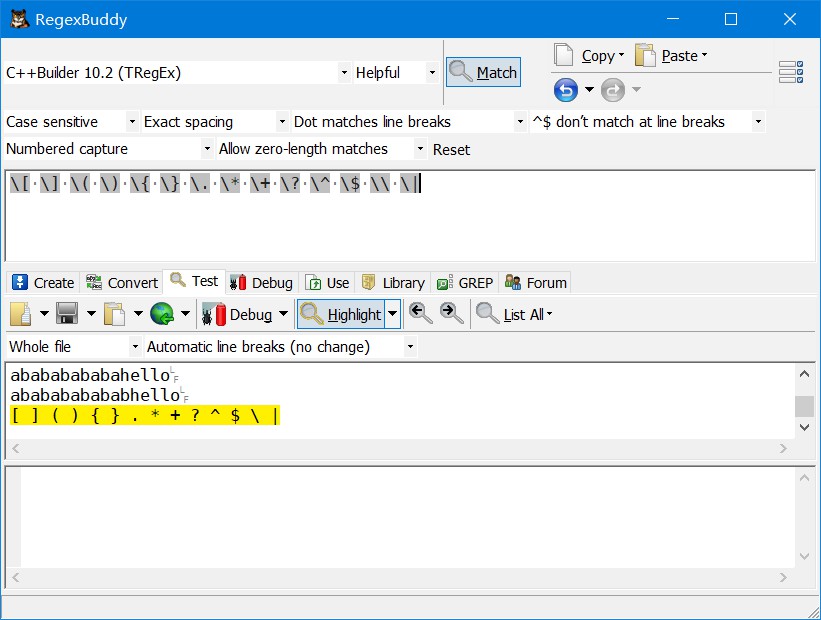
转义字符,用于匹配一些保留的字符
[ ] ( ) { } . * + ? ^ $ \ |
运算符 ^
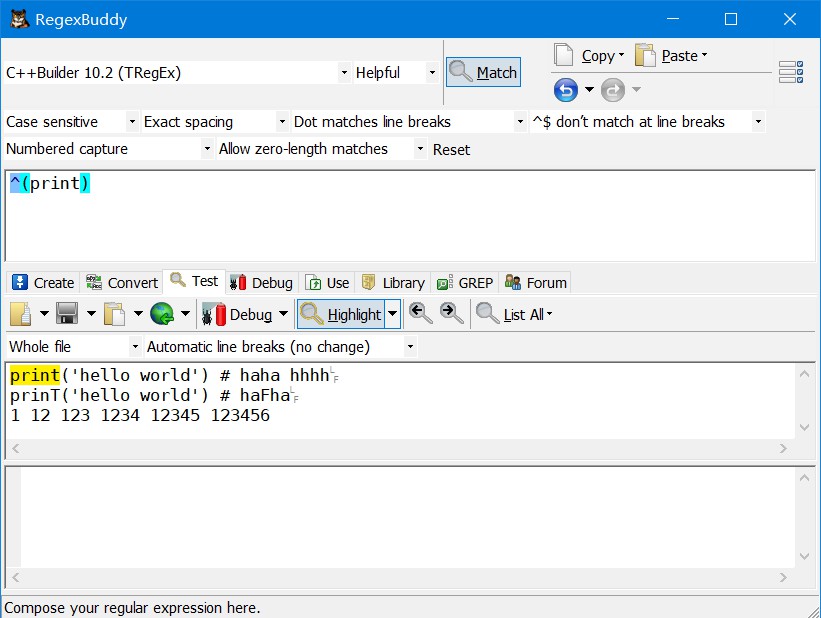
从一行起始开始匹配,^放在字符集前
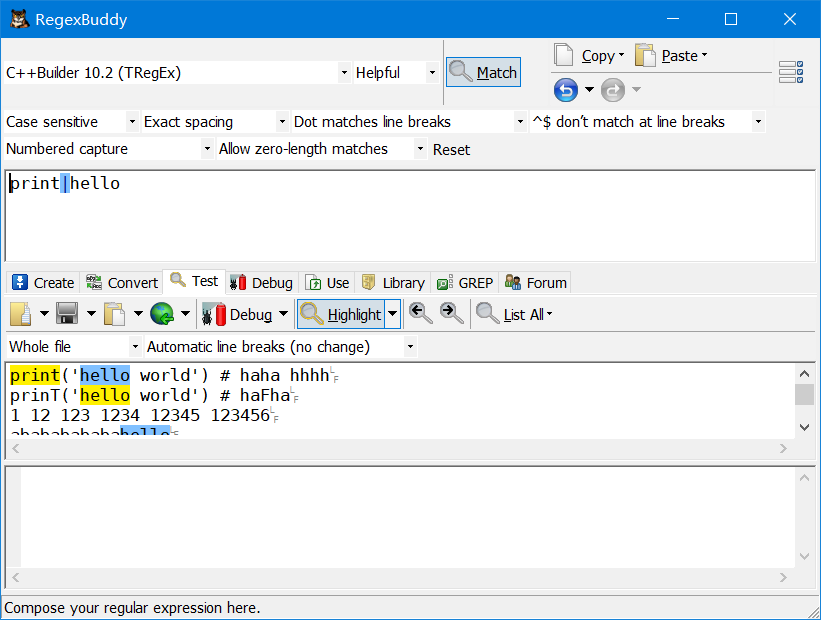
^(print)匹配一行起始的print
运算符 $
从一行末端开始匹配,$放在字符集后
(123456)$匹配一行末尾的123456
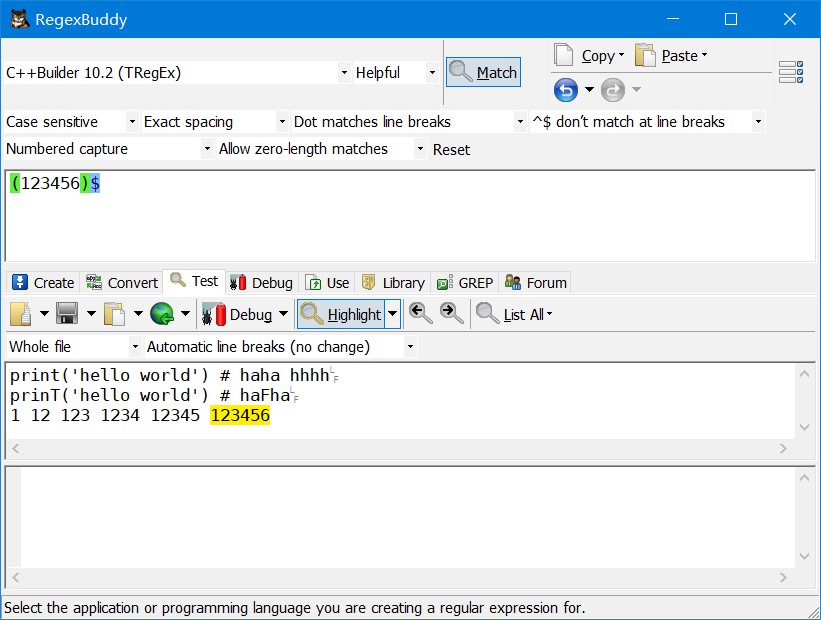
运算符^和$根据正则表达式环境而定,部分环境为全文的起始和末端开始匹配。
📍字符集简写
| 简写 | 描述 |
|---|---|
| . | 除换行符外的所有字符 |
| \w | 匹配所有字母数字,等同于 [a-zA-Z0-9_] |
| \W | 匹配所有非字母数字,即符号,等同于: [^\w] |
| \d | 匹配数字: [0-9] |
| \D | 匹配非数字: [^\d] |
| \s | 匹配所有空格字符,等同于: [\t\n\f\r\p{Z}] |
| \S | 匹配所有非空格字符: [^\s] |
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
| \p | 匹配 CR/LF(等同于 \r\n),用来匹配 DOS 行终止符 |
🔎零宽度断言(前后预查)
| 符号 | 描述 |
|---|---|
| ?= | 正先行断言-存在 |
| ?! | 负先行断言-排除 |
| ?<= | 正后发断言-存在 |
| ?<! | 负后发断言-排除 |
简单来说,就是通过这些断言符号来强调两个字符串的关系,常用于密码复杂度验证,假设有两个字符串aaa和bbb
| 断言式 | 结果 |
|---|---|
| aaa(?=bbb) | 强调aaa后面紧跟着bbb |
| aaa(?!bbb) | 强调aaa后面不跟着bbb |
| aaa(?<=bbb) | 强调bbb前面紧跟着aaa |
| aaa(?<!bbb) | 强调bbb前面不跟着aaa |
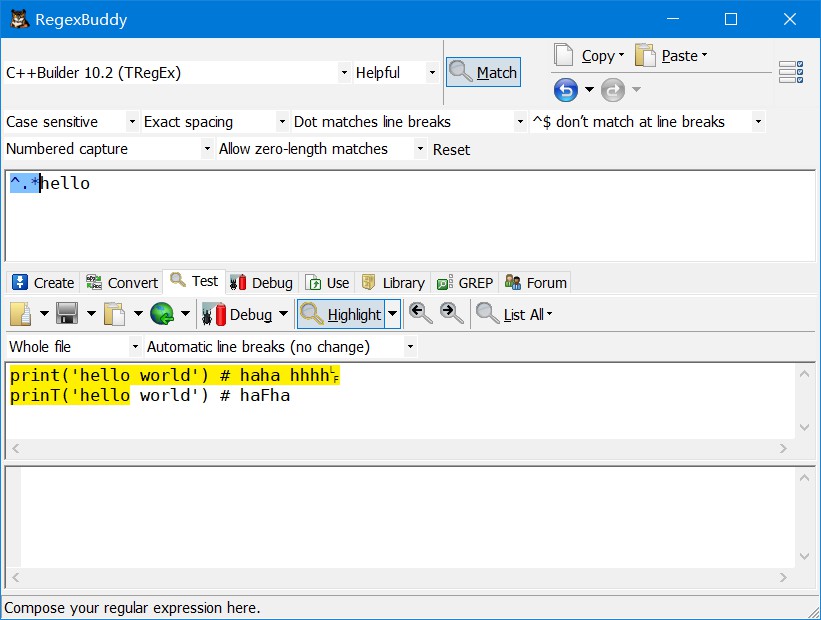
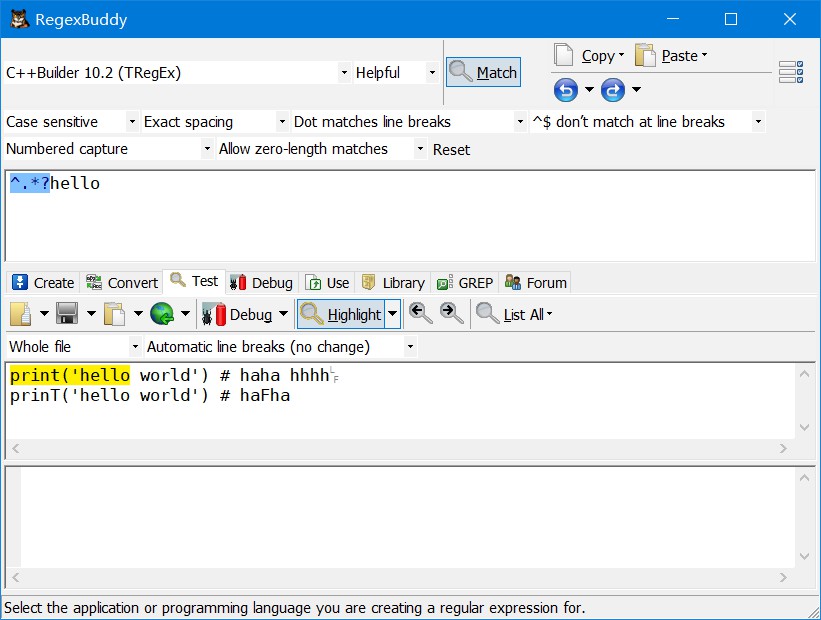
📌贪婪匹配与惰性匹配
正则表达式默认采用贪婪匹配模式,在该模式下意味着会匹配尽可能长 的子串。我们可以使用
?将贪婪匹配模式转化为惰性匹配模式。
贪婪匹配
惰性匹配
⚡⚡⚡ OVER ⚡⚡⚡